Crawling – A Technical Guide

{kind=link}
We have already described a little about crawling in our first article, now we will talk about it more in detail.
This article will cover
• What are crawlers in the language of search engines?
• How they work?
• Potential problems they face on daily basis
Types of crawlers
Crawling is the initial step that search engines take in order to revert the user with adequate results for the search. In simple words, it provides a base to search engines for performing core tasks. These crawlers have their own name and in the case of Google, it is “spider” an algorithm behind this bot keeps changing in order to confer more refined search to the user and decrease the spamming.
How it works
The main function of the crawlers is to find, download and hand over newly created or updated pages to the Google indexer for further processing. The crawler is the algorithm which is responsible for finding your page at first place. These web crawlers functions like your basic website browsers, but they are backed by giant processing speed and storage.
Google Spider is a chain of powerful computers, which are capable of requesting & fetching thousands of web pages at the same time from web servers. Even at this very moment there are numerous web servers working with GoogleBot little bit less to their full efficiency to tackle the continuous searches done by humans. Reason why we have written “little bit less” in the above phrase is because GoogleBot tries its best to avoid the situation of overcrowding and overwhelming of web servers that is why it requests little less than their full efficiency.
Once crawling bots visit your website they initially check “robots.txt” which tells the bots what pages is accessible and which are not.
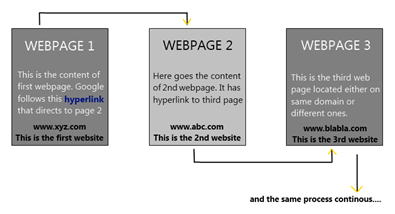
After that, Google spider starts crawling accessible web pages, including links to other websites, spider store those links in “soon to be visited website” and move on to another website.
Later on Indexing Box looks gathers information from collects pages by crawlers.
After crawling your website once crawlers won’t crawl your WebPages again until and unless they have a specific reason to. The best way to attract crawlers is content; update your website with fresh content weekly by this we mean blogs, news, etc. once you have updated the content or made changes in the infrastructure Google bots note that and they frequently come to your website which furthermore increases your chances of ranking well.
With these changes you not only make trustworthy relations with Google bots but also with your users. Your users will come back for high quality interesting content again and again so do crawlers.
Problems That Crawlers Face Even after huge changes in crawling algorithms these crawlers are still facing problems due to their limitations. Following technologies are meant to enhance a user’s website experience, but search engines are struggling to understand these platforms after all how far an algorithm can go.
• JavaScript
• AJAX
• Flash
These digital technologies are considered mandatory in the sphere of crafting an innovative and responsive website design, but from an SEO point of view they can affect your website’s content crawling factor.
These guides would help you in writing these technologies adequately and have more knowledge about them.
Basics of Java Script with HTLMGOODIES
Basics Of AJAX with ELEGANTTHEMES
Adobe Flash WIKIPEDIA Article
There are other forms of content as well, which crawlers find difficult to understand which are mostly images and videos, Google is now becoming sophisticated in terms of understanding images but on the other hand of videos it is struggling.
Adding some content inside the image will still make it difficult for a search engine to understand search engines and they will treat the image as concrete, apart from that a video does enhance your website’s all over the structure and add more depth to it but make sure you add enough content around it to address the purpose of the video.
At the crux we would say your content plays a very vital role in website crawling process as search engines, especially Google prefers written phrases over above technologies. So make sure your content is high quality, relevant and accessible to the search engine crawlers.
Types of crawler
Every search engine possesses a variety of crawlers for different purposes such as image crawling, video crawling and so on. You will have a glimpse of different types of crawlers used by Google at this link Google Web Crawlers with User Agents, this link will also convey the information about these crawlers and their main purpose more briefly.
Each crawler comes with a specific name and version, this version varies with new modified updates and known as a user agent. From the above given link you will be able to update yourself with the different crawling bots along with their user agents.
In our coming articles we will discuss further steps after crawling takes its place effectively.